
こんにちは!
ITエンジニアのYukiです。
200日でのPostgreSQL資格のOSS-DB Gold取得を目指していましたが、今回ですでに211日目です。
オーバーしてしまいましたが、もう少し準備してから受験しようと思います。
今回は、PostgreSQLのトランザクションID周回問題(XID周回問題)について学んだので、解説します。
トランザクションID周回問題とは、簡単に言うと、トランザクションのたびにカウントアップされるXIDが32bit整数(約40億個)で管理されているため、一周すると困るという問題です。
この記事では以下について解説します。
- トランザクションIDが周回するとどんな問題が起きるのか
- PostgreSQLは周回問題をどのように解決しているのか
- トランザクションIDの周回が起きないようにするには
なお、この記事はOSS-DB v2.0の試験が対応するPostgreSQL 11から、2020年リリースの13までの動作に対応しています。(PostgreSQL 14からの新機能でFailsafeモードが追加されていますが、試験範囲から外れるので除きます)
この記事を書いた背景について、トランザクションID周回問題は、Google検索上位の情報でも古かったり間違ってたりが多かったんです。(執筆時の2022年6月現在)
そこで、マニュアルの情報をもとに解説してみます。
トランザクションID周回問題は、OSS-DB Goldの出題範囲にも入っているので、しっかりと理解しておこうと思います。
トランザクションID周回問題とは
トランザクションID周回問題が起きるしくみ
トランザクション周回問題とは、トランザクションID(XID)が半周すると、過去のデータが未来のデータとなるため、見えなくなるという問題です。
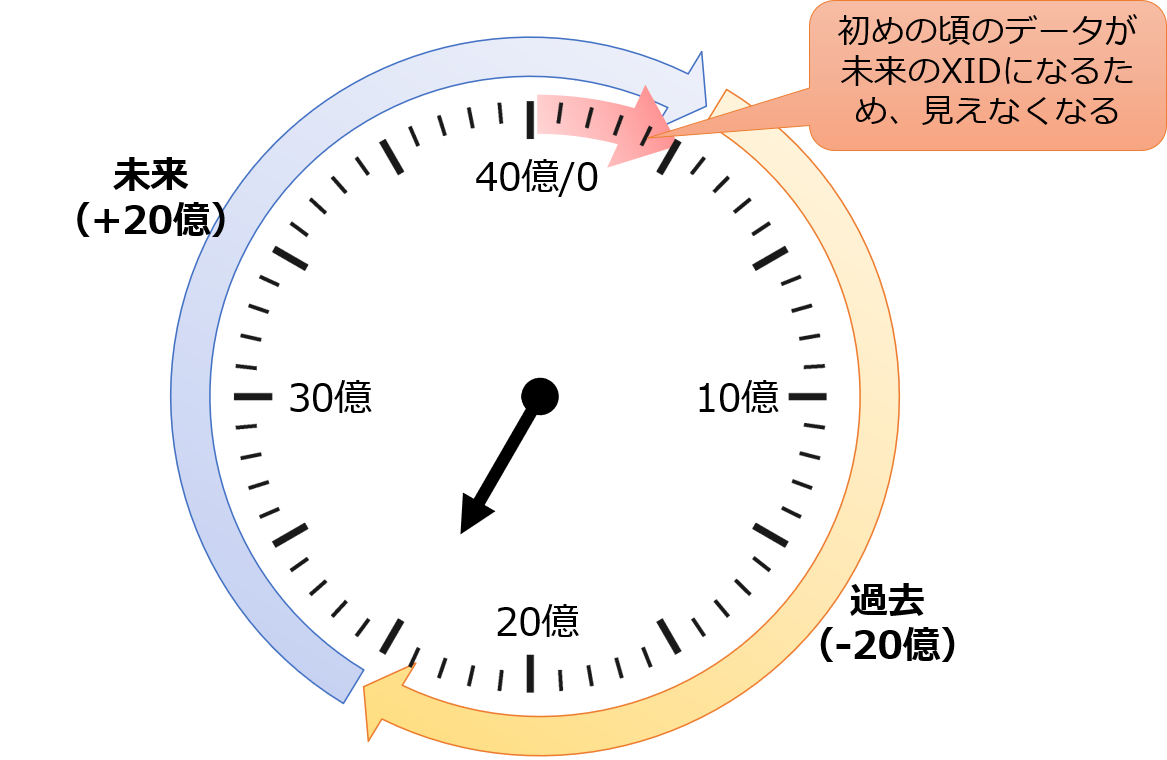
トランザクションIDの周回エラー
(イラスト素材利用:イラストイメージ)
これだけだとよくわからないかもしれません。
- 未来のデータとは何でしょう?
- 未来のデータが見えないというのはどういうことでしょうか?
- なぜ一周ではなく半周なのでしょう?
まず、各トランザクションには、32ビットのトランザクションID(XID)が連番で振られます。
一方で、テーブルの各行には、挿入されたときにXIDが記録されます。更新(UPDATE)時も、PostgreSQLは追記型アーキテクチャですので、削除→挿入の動きとなるため、そのときのXIDが記録されます。
未来のデータとは
現在のトランザクションIDから見て、古いXIDは過去のデータ、新しいXIDは未来のデータを表します。
未来のデータが見えないとは
MVCCでは、複数のトランザクションが並行して動作するとき、自分のトランザクションより古いXIDの行は見える一方、自分より新しいXIDの行は見えなくなっています。これが未来のデータは見えないということです。
トランザクションIDの周回エラーについて、マニュアルから引用します。上記で説明したことが書かれています。
PostgreSQLのMVCCトランザクションのセマンティクスは、トランザクションID(XID)番号の比較が可能であることに依存しています。 現在のトランザクションのXIDよりも新しい挿入時のXIDを持ったバージョンの行は、「未来のもの」であり、現在のトランザクションから可視であってはなりません。 しかし、トランザクションIDのサイズには制限(32ビット)があり、長時間(40億トランザクション)稼働しているクラスタはトランザクションの周回を経験します。 XIDのカウンタが一周して0に戻り、そして、突然に、過去になされたトランザクションが将来のものと見えるように、つまり、その出力が不可視になります。 端的に言うと、破滅的なデータの損失です。 (実際はデータは保持されていますが、それを入手することができなければ、慰めにならないでしょう。) これを防ぐためには、すべてのデータベースにあるすべてのテーブルを少なくとも20億トランザクションごとにバキュームする必要があります。
(PostgreSQL 13.1文書 「24.1.5. トランザクションIDの周回エラーの防止」より)
マニュアルの文書だと固いですが、同じ内容ですね。
なぜ一周ではなく半周で見えなくなるのか
初め「20億トランザクションごとに」というのがよくわかりませんでした。
32ビットなら、40億トランザクションまで大丈夫なのではないかと思いました。
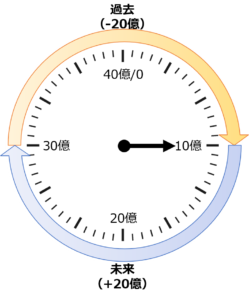
XIDが10億のときの様子
マニュアルの「20億トランザクションごとにバキューム」は、なぜ40億ではないのでしょうか? 32ビットなら40億ほどあるはずです。これは、PostgreSQLではトランザクションIDが循環しているためです。
時計のようなものをイメージしてください。左図のように現在のトランザクションIDが10億とすると、そこから-20億分が過去を、+20億分が未来を表します。トランザクションIDが20億分進むと、それまで過去だったデータが未来と判定されてしまうため、見えなくなります。
トランザクションID周回時のエラーの例
トランザクションID周回時に出力されるエラーログをPostgreSQLのマニュアルから引用します。
周回ポイントまで1100万トランザクションを切るとWARNINGが出力され始めます。
WARNING: database “mydb” must be vacuumed within 177009986 transactions HINT: To avoid a database shutdown, execute a database-wide VACUUM in “mydb”.
(PostgreSQL文書13.1 「24.1.5. トランザクションIDの周回エラーの防止」より)
HINTに従い、スーパーユーザで手動バキュームを実行するとトランザクションIDの周回は回避できます。
バキュームで回避できるんですね。
なぜ回避できるかは、後で説明します。
この警告を無視し続け、周回ポイントまで100万トランザクションを切ると、PostgreSQLは以下のエラーを出力して停止します。
ERROR: database is not accepting commands to avoid wraparound data loss in database “mydb”
HINT: Stop the postmaster and vacuum that database in single-user mode.
(PostgreSQL文書13.1 「24.1.5. トランザクションIDの周回エラーの防止」より)
もしこの問題が発生した場合は、サーバ停止後、シングルユーザモードでサーバ起動してVACUUMを実行することで復旧します。
最後100万分のトランザクションは、復旧作業用に残されているんですね。
トランザクションID周回問題の解決手法
先ほどのログに出ていたように、実はトランザクションID周回問題は、バキュームにより解決します。どのような仕組みなのでしょうか?
凍結(FREEZE)
バキュームにより、テーブルの古いXIDの行に凍結状態のフラグが立ちます。凍結状態になった行は、どのトランザクションからも過去のものと判定されます。
これで過去と未来が逆転することがなくなりますね。
なお、凍結される行は、vacuum_freeze_min_age(デフォルト 5千万)が経過した行です。凍結処理が無駄にならないように、あまり頻繁には凍結しないようになっています。行が変更されなくなってから凍結するのがタイミング的には理想です。
3種類のバキューム
バキューム時には、すべてのページが走査されるわけではありません。走査のされ方、起動の仕方によって、3種類のバキュームがあります。(※テーブルを再作成するVACUUM FULLは無関係です)
- 通常のバキューム
- 積極的なバキューム
- 周回防止用の自動バキューム
通常のバキューム
通常のバキュームでは、無効行がないページは、たとえ古いXIDがあっても読み飛ばします。つまり、古いXIDが凍結されずに残ります。
積極的なバキューム
次に、積極的なバキュームでは、無効行も凍結されていないXIDもないページを読み飛ばします。つまり、十分古いXID(vacuum_freeze_min_age以上経過したXID)の行は凍結されます。積極的なバキュームのタイミングは、vacuum_freeze_table_ageパラメータ(デフォルト 1.5億)で制御され、トランザクションがvacuum_freeze_table_age – vacuum_freeze_min_age分経過すると実行されます。
周回防止用の自動バキューム
最後に、周回防止用の自動バキュームは、強制的に実行されるバキュームです。たとえ自動バキュームをOFFに設定した場合でも実行されます。autovacuum_freeze_max_ageパラメータ(デフォルト 2億)分よりも古いXIDを持つテーブルに対して実行されます。
適切なタイミングで積極的なバキュームが、そして最後の手段として周回防止用の自動バキュームが行われることで、トランザクションIDの周回が防止されているわけですね。
トランザクションIDの周回が起きないようにするには
トランザクションIDの凍結には、値が小さいほうから順に、以下の3つのパラメータが関連しています。
- vacuum_freeze_min_age(デフォルト 5千万)
- vacuum_freeze_table_age (デフォルト 1.5億)
- autovacuum_freeze_max_age (デフォルト 2億)
自動バキュームで問題が起きなければ、トランザクションIDが周回する事態にはならないと考えられます。以下が理由です。
- 自動バキュームがONの場合、積極的なバキュームが自動で実行される。
- 自動バキュームがOFFのテーブルでも、周回防止の自動バキュームが強制的に実行される。(そもそもそのようなテーブルは、定期的に手動バキュームを実行しているテーブルか、変更がない静的なテーブルの場合と考えられる)
逆に自動バキュームで問題が起きて、凍結に失敗するようなら、周回問題が発生する恐れがあります。
自動バキュームが終わらない場合は、その原因を調査しましょう。たとえば以下のような問題が考えられます。
- ロングトランザクション
- テーブルの肥大化
ロングトランザクションの場合は、長時間実行中のクエリがないか、未コミットのトランザクションがないかなどを確認しましょう。
テーブルの肥大化により、バキュームが終わらない場合は、パーティショニングを検討するとよいかもしれません。
まずは、バキュームで問題が起きていないか調査することになるかと思います。
暫定で対処するには、原因や状況により、ロングトランザクションを停止させてから手動バキュームを実行するとか、シングルユーザモードで起動しなおして、スーパーユーザでバキュームを実行するといった方法が考えられます。
補足
バージョンにより異なる点について補足します。
特殊なXID
凍結された行のXIDは、特別な値である2(FrozenTransactionId)として扱われます。実は2以下のXIDは、以下のように特殊な意味を持っていて、通常使われません。
- 1(BootstrapTransactionId)・・・initdb時に挿入された行を表す
- 2(FrozenTransactionId)・・・凍結状態の行を表す
PostgreSQL 9.4より前のバージョンでは凍結フラグを立てるのではなく、XIDを2(FrozenTransactionId)に更新していました。そのため、9.4より前からアップグレードしたDBの場合、XIDが2(FrozenTransactionId)の行が存在することがあります。
バージョン9.4以降は、凍結フラグが立つだけです。XIDは変更されません。
古い情報だとXIDが「2」に更新されると書かれています。
学習に使った『内部構造から学ぶPostgreSQL 設計・運用計画の鉄則』でも『「2」に上書き』となってました。
注意しましょう。
[PR]<『[改訂3版]内部構造から学ぶPostgreSQL―設計・運用計画の鉄則』をAmazonで探す>
まとめ
トランザクションID周回問題について、説明しました。
PostgreSQLでは、バキューム時に凍結フラグを立てることで、約40億のトランザクションIDが一周する問題を解決していました。現在のXIDを中心に、-20億分が過去を表し、+20億分が未来を表します。
また、積極的なバキュームを行うことで、PostgreSQLが自動で凍結を行ってくれていました。積極的なバキュームが追いつかない場合は、周回防止の自動バキュームが強制的に実行されました。
万が一、トランザクションID周回時のエラーが発生するような場合は、バキュームに問題が起きていないか調査するのがよいでしょう。
トランザクションID周回問題についていろいろと調べたおかげで、大分理解が進みました。
公式サイトの例題を2周解き終わって、当初予定していた学習は完了したのですが、前回まとめたOSS-DB Gold Ver.1.0から2.0の変更点で、理解が足りないところがあるようです。
そのあたりをもう少し勉強しようと思います。
最後までご覧いただき、ありがとうございました。
こんなことも知りたいといったご質問や間違ってるよといったご指摘、ご感想などありましたら、ページ一番下からお気軽にコメントください。
この記事が役に立ちましたら、下のボタンからシェアしていただけると嬉しいです。
それでは。
お薦めの本(PR):
[PR]<『[改訂3版]内部構造から学ぶPostgreSQL―設計・運用計画の鉄則』をAmazonで探す>


コメント